
深入理解高速缓存工作原理
为什么需要高速缓存
早期 CPU 相比现在的 CPU 比较简单,没有 Cache 的计算机系统的简化模型,CPU在执行时需要的指令和数据通过内存总线和系统总线由内存传送到寄存器,再由寄存器送入ALU)。
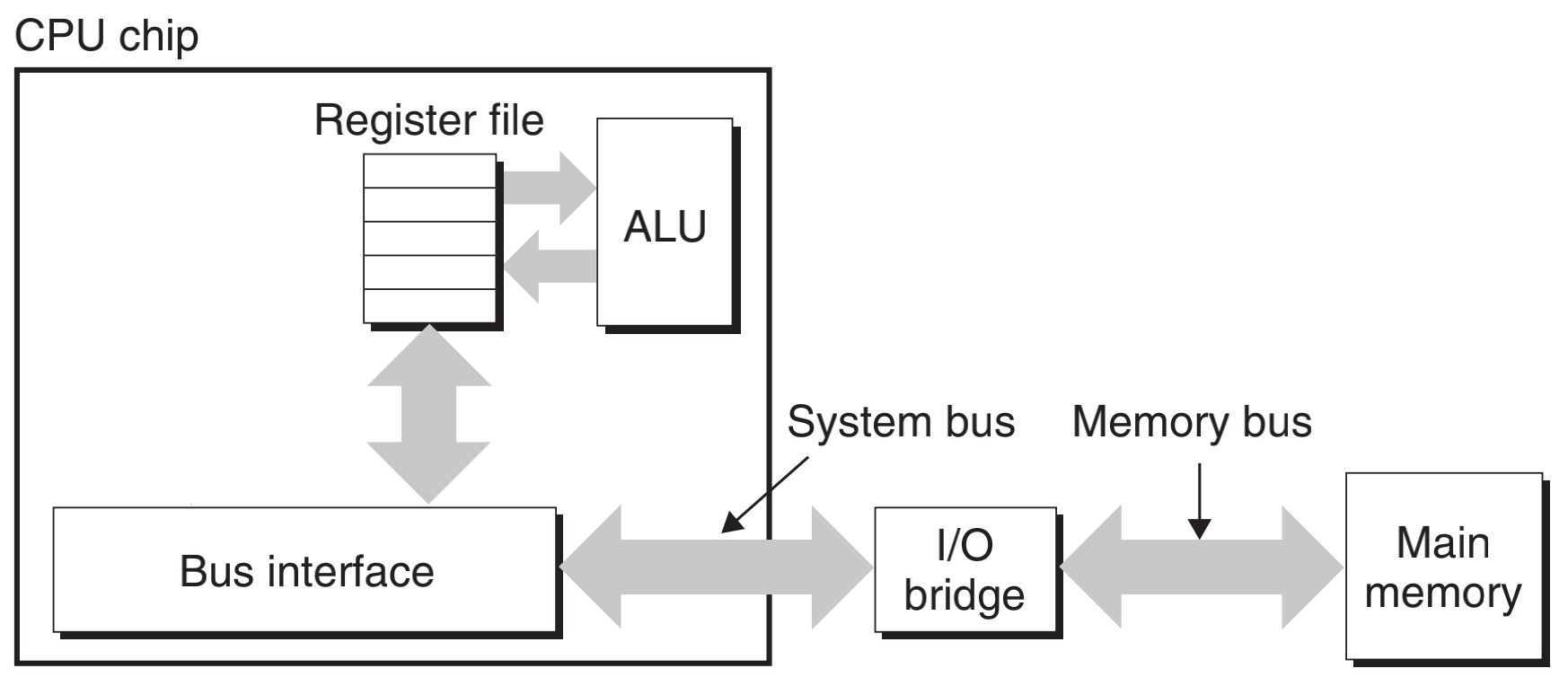
那时候,CPU 内核的频率与内存总线的频率相当。内存访问只比寄存器访问慢一点。随着 CPU 内核频率不断增加,内存总线的频率和 RAM 芯片的性能并没有成比例增加。
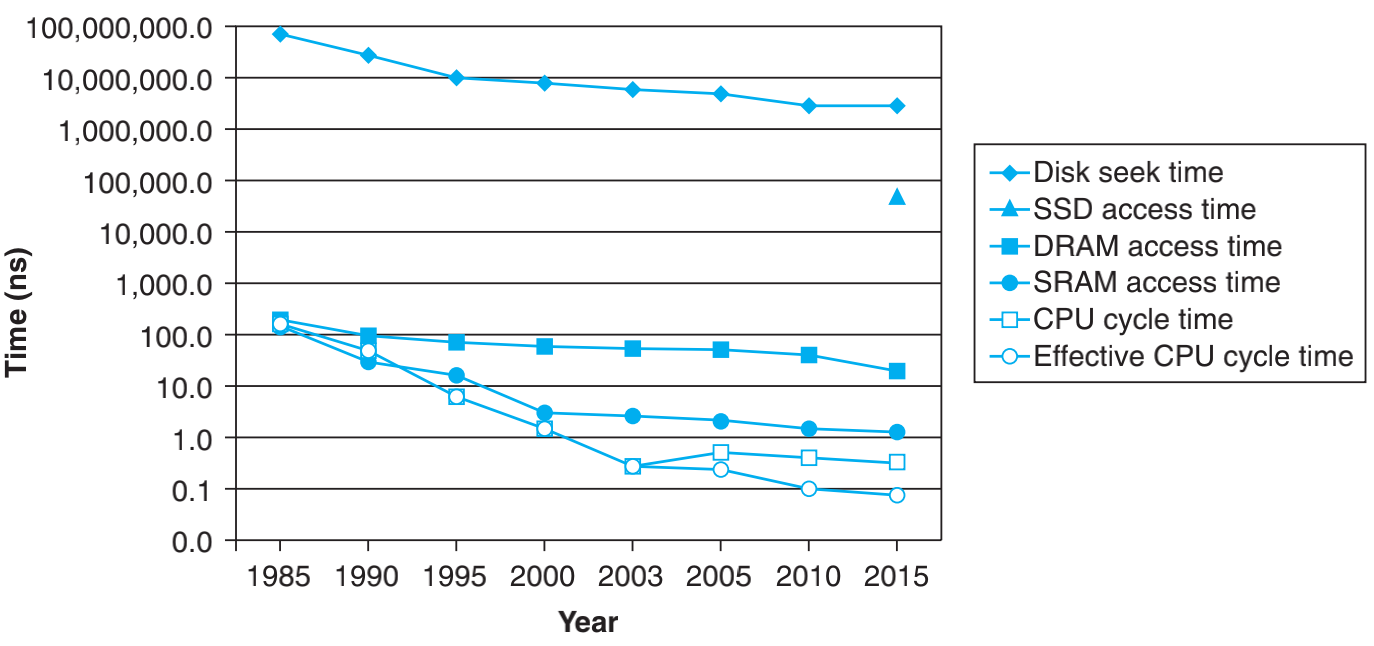
下图展示了CPU和主存(DRAM)、磁盘速度上的差距。可以看到,CPU的速度大概是主存的几十倍,如果没有Cache(SRAM),这就出现了 CPU 等待 I/O 访存的现象,致使CPU空等一段时间,甚至可能等待几个主存周期,从而降低了CPU 的工作效率。
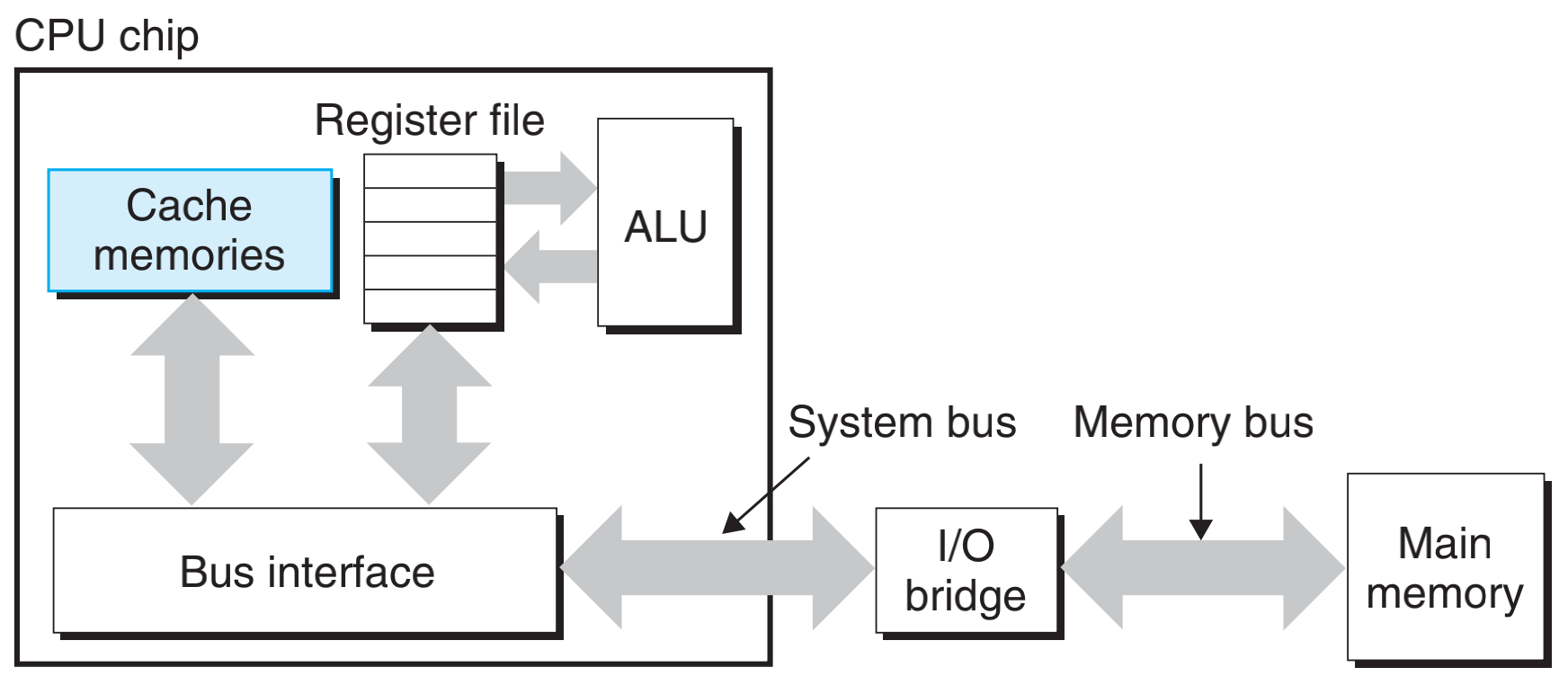
在 CUP 和 DRAM 之间引入高速 SRAM,来弥补这种差距,当 CPU 需要数据时,先查 SRAM(Cache)中,如果在 Cache 中可以查询到,叫作缓存命中,则就不需要访问 DRAM 了,节约时间。
程序局部性原理
为了充分发挥 Cache 的能力,使得机器的速度能够切实的得到提高,必须要保障 CPU 访问的指令或数据大多情况下都能够在 Cache 中找到,这样依靠程序访问的局部性原理。
- 时间局部性:最近访问的数据可能在不久的将来会再次访问
- 空间局部性:位置相近的数据常常在相近的时间内被访问
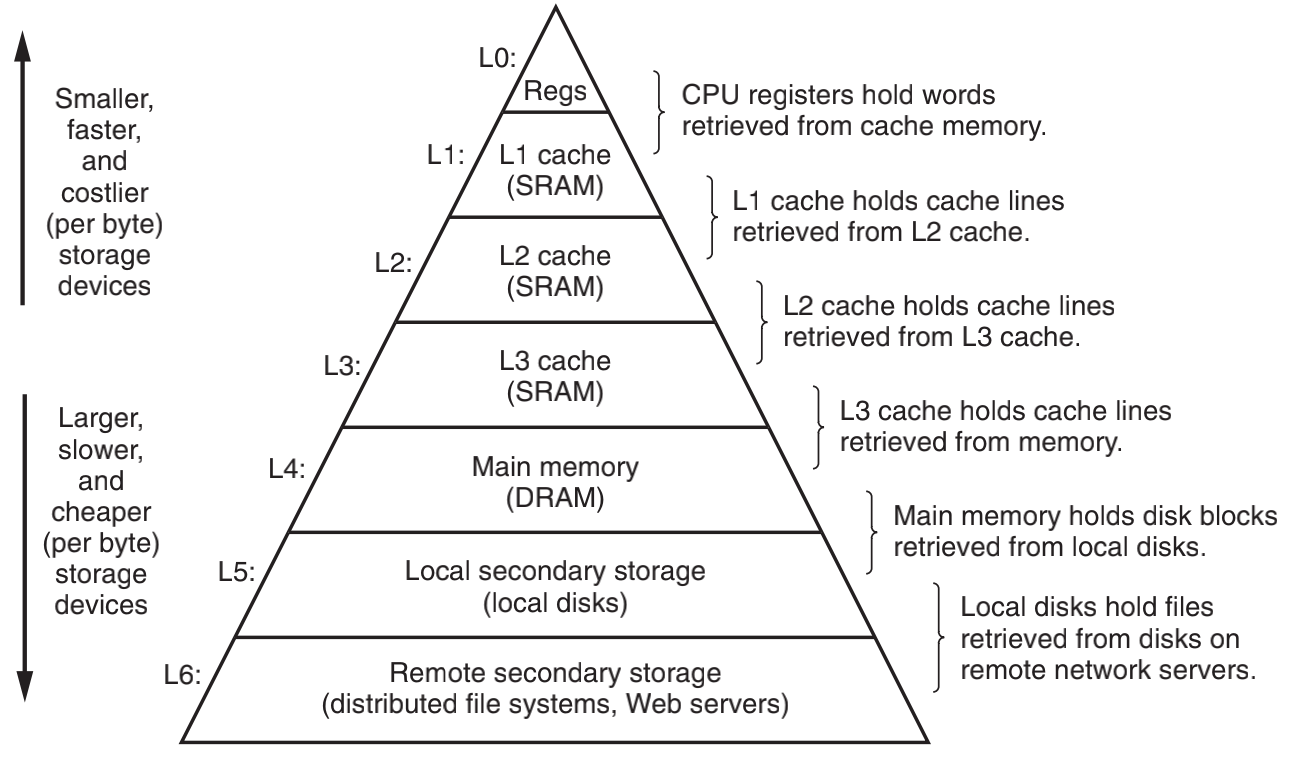
存储山
由于不同的存储技术在存储速度和造价上相差巨大,为了高效的访问数据,现代计算机的存储系统会把最常用的数据放在读存速度快的存储设备上,而把不常用的数据放在读存速度慢的存储设备上。
存储器系统是一个具有不同容量、成本和访问时间的存储设备的层级结构。从上往下容量越来越大,但访问速度越来越慢。上一层做为下一层的缓存来存储访问频率更高的数据,
比如,CPU 寄存器保存着最常用的数据。靠近 CPU 的小的、快速的高速缓存存储器是内存上一部分数据和指令的缓冲区域。主存缓存磁盘上的数据,而这些磁盘又常常作为存储在通过网络连接的其他机器的磁盘或磁带上的数据的缓冲区域。存储层次如下:
高速缓存原理
假设计算机储存地址为 m 位,形成 M = 2^m 个不同的地址,就会形成 S = 2^s 个缓存组(cache set),每组包含 E 个高速缓存行(cache line),每行包含一个有效位(valid bit)指明这个行是否有效,t 个标记位(tag bit)和 B = 2^b 个缓存数据块。
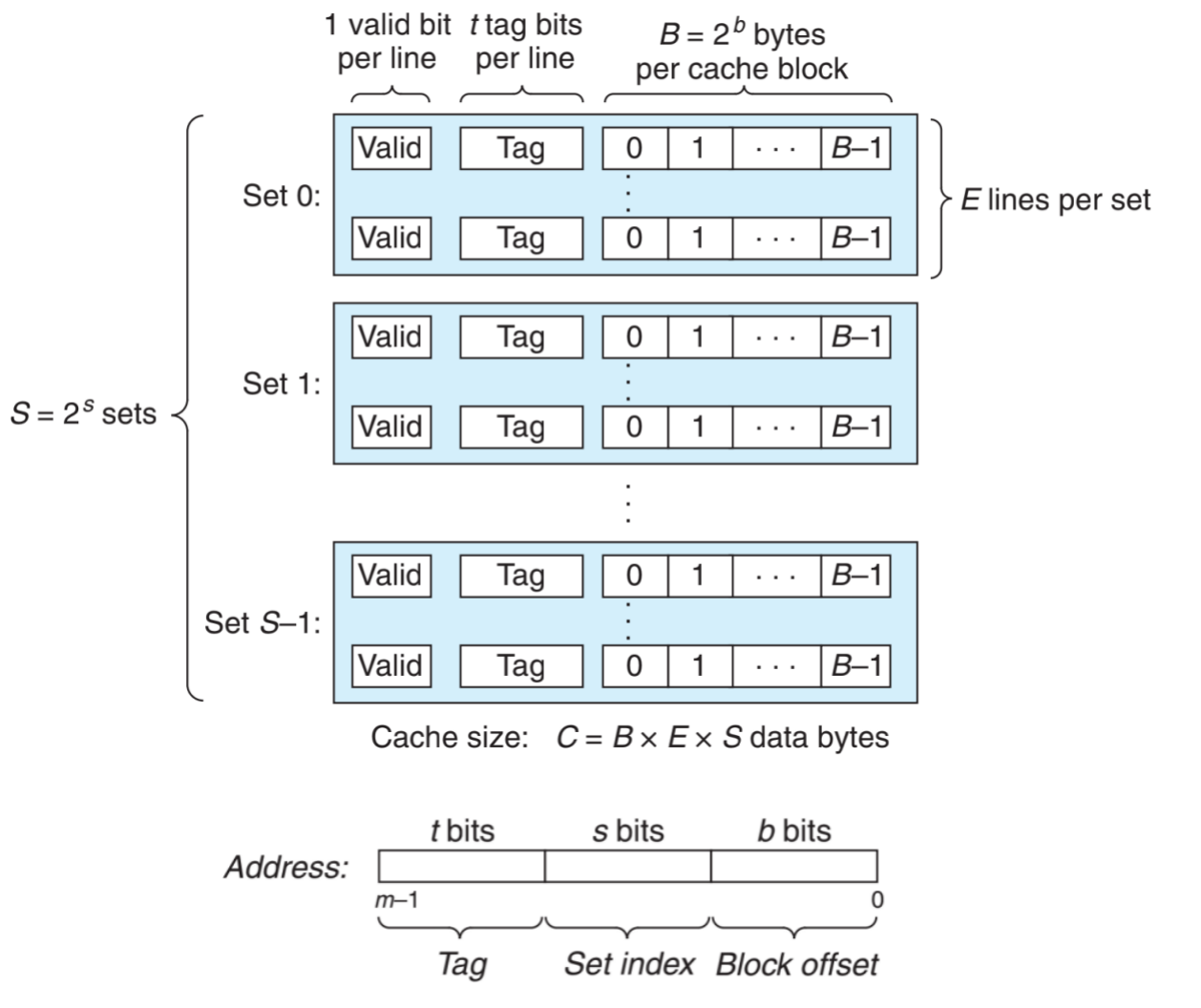
Cache由硬件管理,硬件在得到内存地址后会将地址划分为三个部分
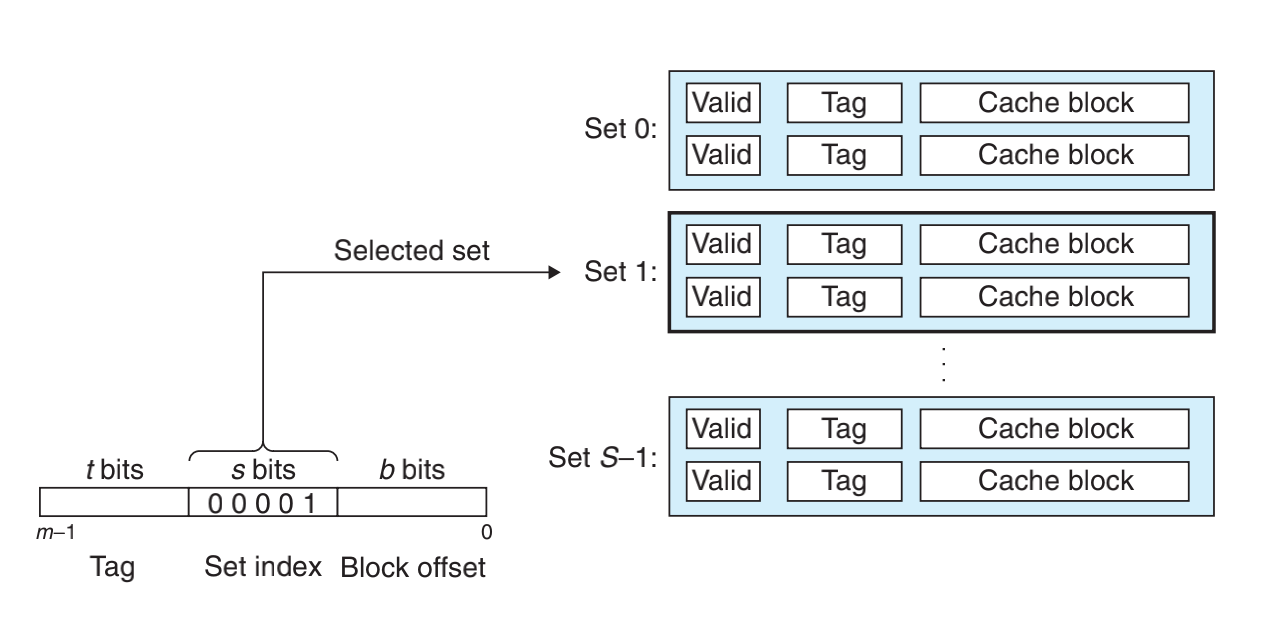
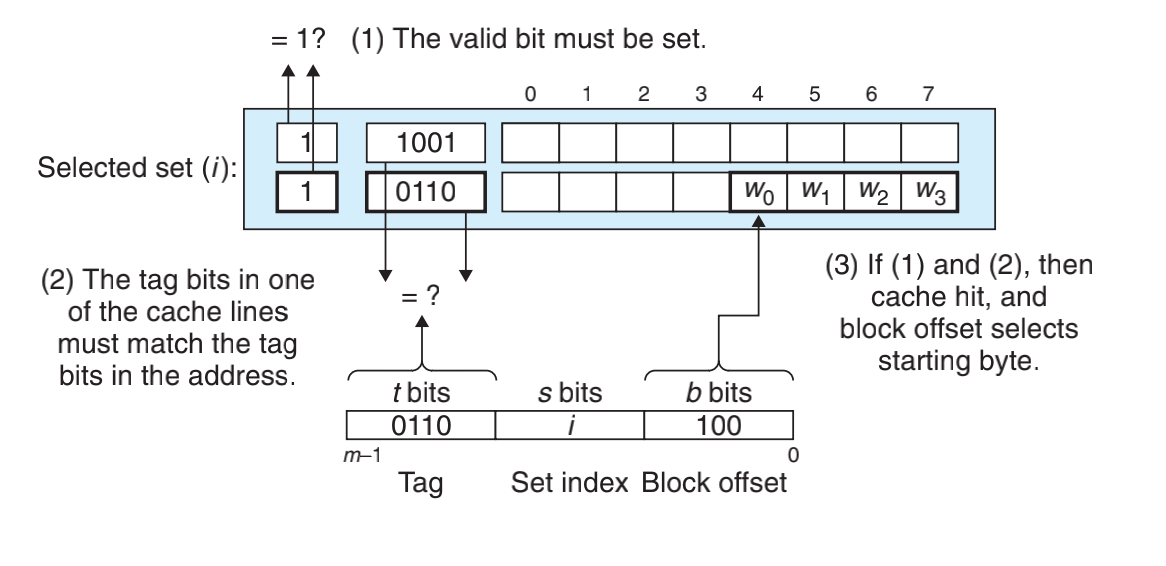
首先根据组下标选择一个组,然后将地址中的标签与被选中组的每个行中的标签进行比较,如果标签相等,且有效位为1,则 Cache 命中,再根据块偏移从行中选出相应的数据。
假设计算机储存地址为 m 位,形成 M = 2^m 个不同的地址,就会形成 S = 2^s 个缓存组(cache set),每组包含 E 个高速缓存行(cache line),每行包含一个有效位(valid bit)指明这个行是否有效,t 个标记位(tag bit)和 B = 2^b 个缓存数据块
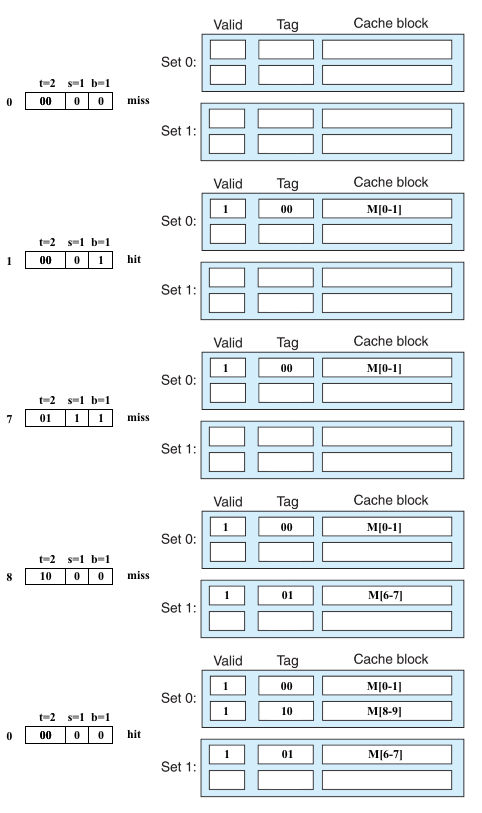
假设 m = 4,t = 2,s = 1,b = 1,E = 2
可知:
- M = 2^m = 2^4 = 16
- S = 2^s = 2^1 = 2
- B = 2^b = 2^1 = 2
分别读取地址为 0、1、7、8、0 这几个地址,看看缓存能命中哪些?
具体过程如图:
高速缓存不命中替换
如果 CPU 请求的数据不在任何一行中,那么缓存不命中,如果有空行的话就把数据缓存到空行中,如果没有空行,那我们必须选择一个非空行替换。可以使用 LRU 算法来替换。
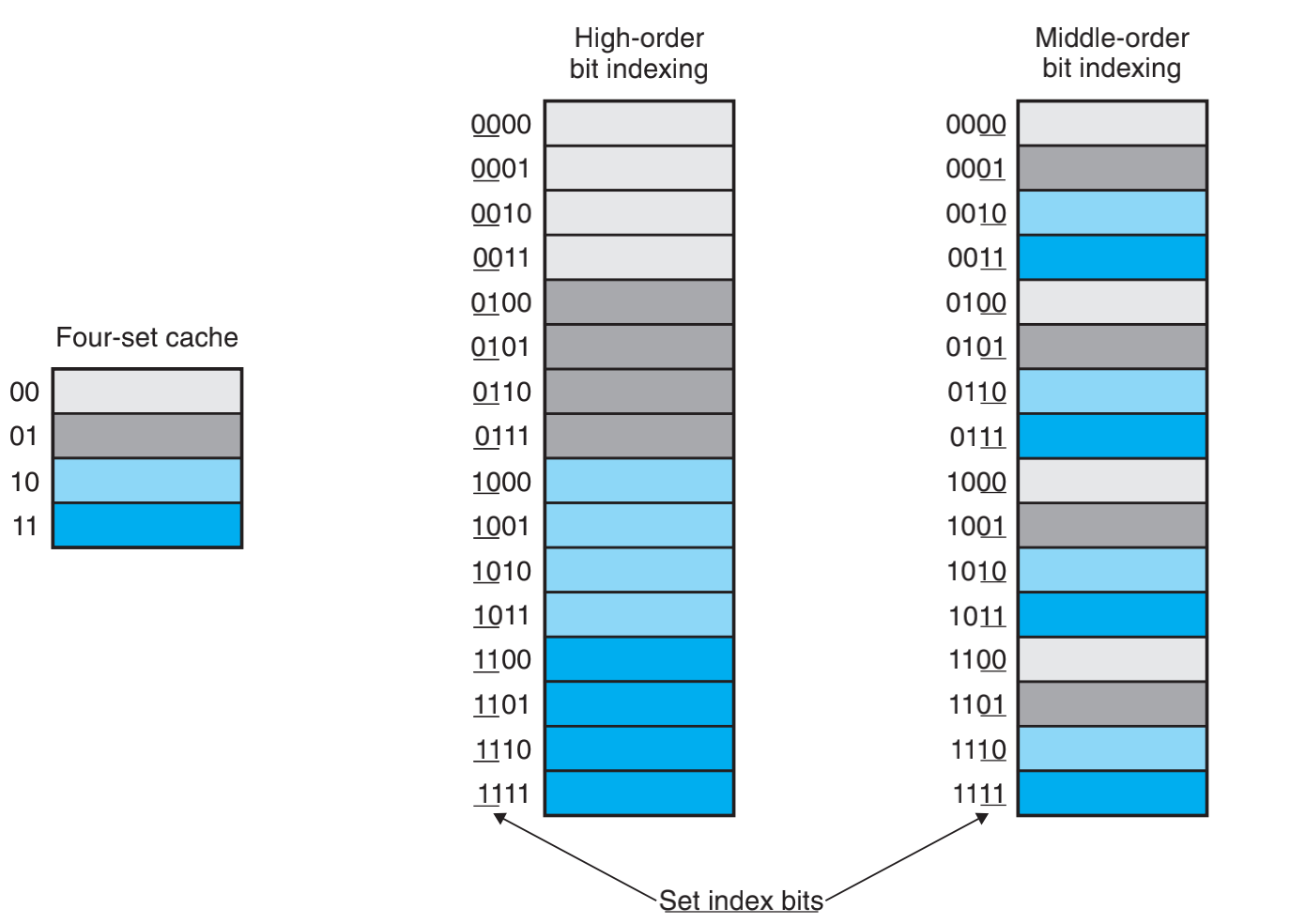
为什么使用中间位来做索引?
假设我们有一个缓存组可以缓存四块,如果我们去 0000 这块数据,并且把 0001、0002 和 0003 这三块数据加入缓存中,就会发现,使用高位缓存只能缓存一块数据,而使用中间位来索引可以缓存四块数据。所以使用高位做缓存缓存的使用效率很低。
高速缓存读与写
高速缓存读
首先,在高速缓存中查找所需字 w 的副本。如果命中,立即返回字 w 给CPU。如果不命中,从存储器层次结构中较低层中取出包含字 w 的块,将这个块存储到某个高速缓存行中,然后返回字 w。
高速缓存写
写命中
直写(write-through),写一个已经缓存了的字w(写命中,write hit),立即将w的高速缓存块写回到紧接着的低一层中。
写回(write-back),尽可能的推迟更新,只有当替换算法要驱逐这个更新过的块时,才把写到紧接着的低一层中。高速缓存必须为每一个高速缓存行维护一个额外的修改位(dirty bit),表明这个高速缓存块是否被修改过。
写不命中
写分配(write-allocate),加载相应的低一层中的块到高速缓存中,然后更新这个高速缓存块。
非写分配(not-write-allocate),避开高速缓存,直接把这个字写到低一层中。
Cache 失效的三种原因
- Cold miss:刚刚使用Cache时Cache为空,此时必然发生Cache miss。
- Capacity miss:程序最经常使用的那些数据(工作集,working set)超过了Cache的大小
- Conflict miss:Cache容量足够大,但是不同的数据映射到了同一组,从而造成Cache line反复被替换的现象。
高速缓存结构
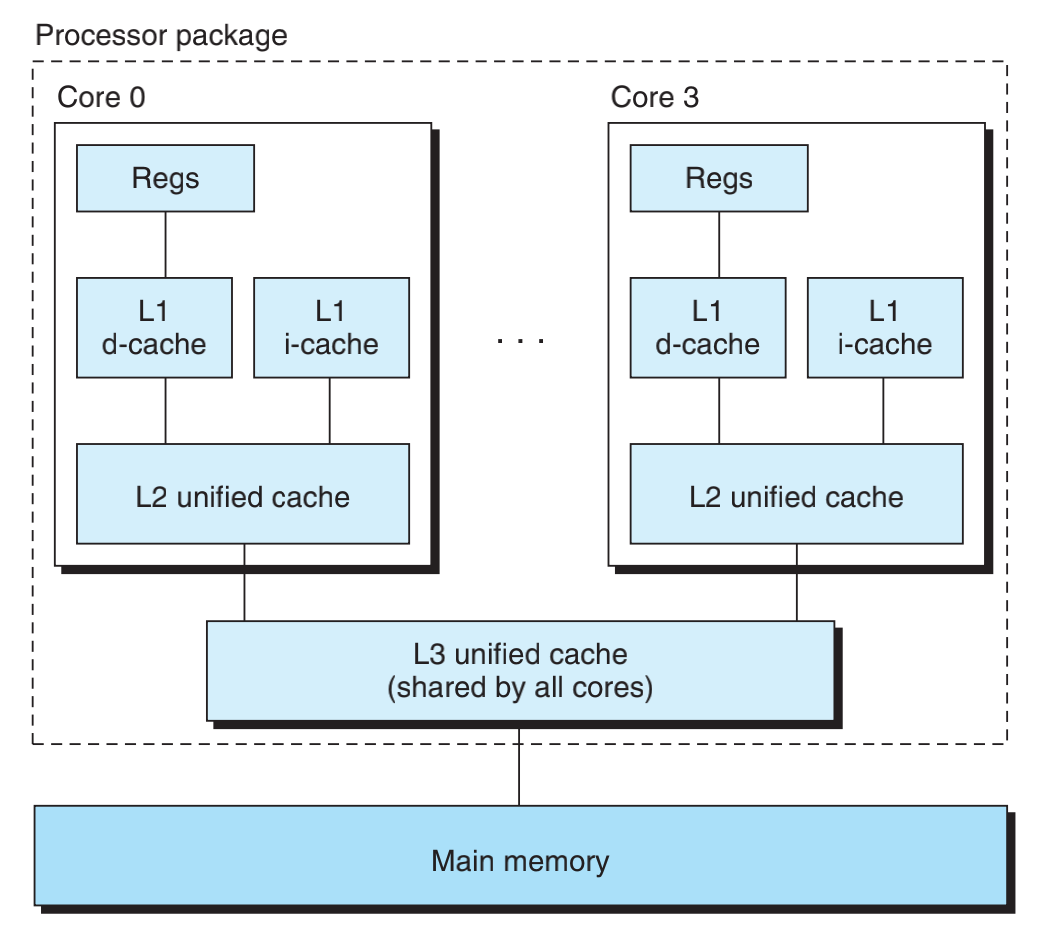
我们看看 Intel Core i7 处理器的高速缓存层次结构。每个 CPU 芯片有四个核。每个核有自己的 L1 i-cache(指令高速缓存)、L1 d-cache(数据高速缓存)、和 L2 统一高速缓存。以及 L3 为所有核共享高速缓存。所有的缓存都是集成在 CPU 芯片上。
下面指标高速缓存类型(Cache Type)、访问周期(Access time)、缓存大小(Cache size)、一组有多少行(Assoc)、块大小(Block size)以及组数(Set)。

编写高速缓存友好代码
假设我们需要来计算一个二维数组的和,有两种方式分别是按行计算和按列计算。
假设我们高速缓存为 4 字,可以缓存 4 和 int 的值。
按行计算
int sumarrrayrows(int a[M][N]) { |
当我们加载地址为1的数,会把 2、3和4地址的数据加载到高速缓存中,如果是按行,后面这几个就会缓存命中。
具体缓存命中情况如图:

按列计算
int sumarrraycols(int a[M][N]) { |
当我们加载地址为1的数,会把 2、3和4地址的数据加载到高速缓存中,然而我们下个取得是 5 所以缓存不命中,同时会把 6、7和8地址加到缓存中。接着下个取地址为9的值,缓存又不命中。
具体缓存情况如图:

我们看上去只是调换了一下顺序,缓存命中相差很大,所以编写高速缓存友好代码。
总结
学习到了高速缓存原理,以及编写高速缓存友好代码。

