
汇编入门
从 C 语言到机器码
先从一个非常简单的程序来看编译过程中发生了那些步骤。
|
我们在 Unix 系统上终端上使用 GCC 进行编译:
> gcc -o hello hello.c |
这里 GCC 编译器把 hello.c 源文件翻译成可执行文件 hello,这个过程一共可以分为 4 步骤:
- 预处理器(Pre-processor):把头文件插入到程序文本中,得到
hello.i文件 - 编译器(Compiler):编译成汇编语言,把
hello.i转换为hello.s - 汇编器(Assember):将汇编语言翻译成机器语言,得到
hello.o文件 - 连接器(Linker):把
printf函数从print.o以某种方式合到hello.o程序中,得到hello可执行文件

当我们用高级语言编程的时候(比如 C 语言,Java 语言),编译器为我们屏蔽了很多机器级别的实现。当使用汇编写程序的时候,程序员需要指定程序来执行计算的低级指令。
高级语言提供的更高抽象级别进行工作会更加高效和可靠。编译器提供的类型检查有助于检测许多程序错误,并确保我们以一致的方式引用和操作数据。
使用现代的优化编译器,生成的代码通常至少与熟练的汇编语言程序员手动编写的代码效率相同。最重要的是,可以在许多不同的机器上编译和执行以高级语言编写的程序,而汇编代码是高度机器特定的。
既然编译器这么 智能,那我们还要学习汇编呢?
- 能够阅读和理解汇编代码是一项很重要的技能
- 理解编译过程的优化能,分析代码中的隐含低效的代码,提高代码效率
- 挖掘代码中隐藏漏洞,增加安全性
汇编入门
我们先写一个简单的 C 语言代码文件 mstore.c 如下:
long mult2(long, long); |
在命令行中使用 -S 选项可以看到 C 语言编译产生的汇编代码:
> gcc -Og -S mestore.c |
打开 mestore.c 文件,除去一些不重要的信息,得到如下汇编代码:
multstore: |
每一行都对对应一条机器指令,比如 pushq 指令是把寄存器中 %rbx 压入程序栈中。
如果我们使用 -c 命令行选项,GCC 会编译并汇编代码生成 mestore.o 文件
> gcc -Og -c mstore.c |
在 mestore.o 文件中有一段字节序列为:
53 48 89 d3 e8 00 00 00 00 48 89 03 5b c3 |
我们通过反汇编 mestore.o 文件
> objdump -d mestore.o |
结果如下,发现反汇编和前面手动编译的代码基本相似。
0000000000000000 <multstore>: |
数据格式
字(word)表示 16 位数据类型,所以是双字(double words)表示 32 位数据类型,四字(quad words)表示 64 位。
| C 声明 | Intel 数据类型 | 汇编代码后缀 | 大小(字节) |
|---|---|---|---|
| char | 字节 | b | 1 |
| short | 字 | w | 2 |
| int | 双字 | l | 4 |
| long | 四字 | q | 8 |
| char * | 四字 | q | 8 |
| float | 单精度 | s | 4 |
| double | 双精度 | l | 8 |
大多数 GCC 生成的汇编代码指令都有一个字符的后缀,表明操作数的大小。例如数据传送指令有四个变种:movb (传送字节)、moww(传送字)、movl (传送双字) 和 movq (传送四字)。
注意两点:
- 后缀用
l表示双字,是因为 32 位数被看成长字(long word) - 4 字节整数和 8 字节双精度浮点数都用
l后缀,并不会产生歧义,因为浮点数使用的不同指令和寄存器
访问信息
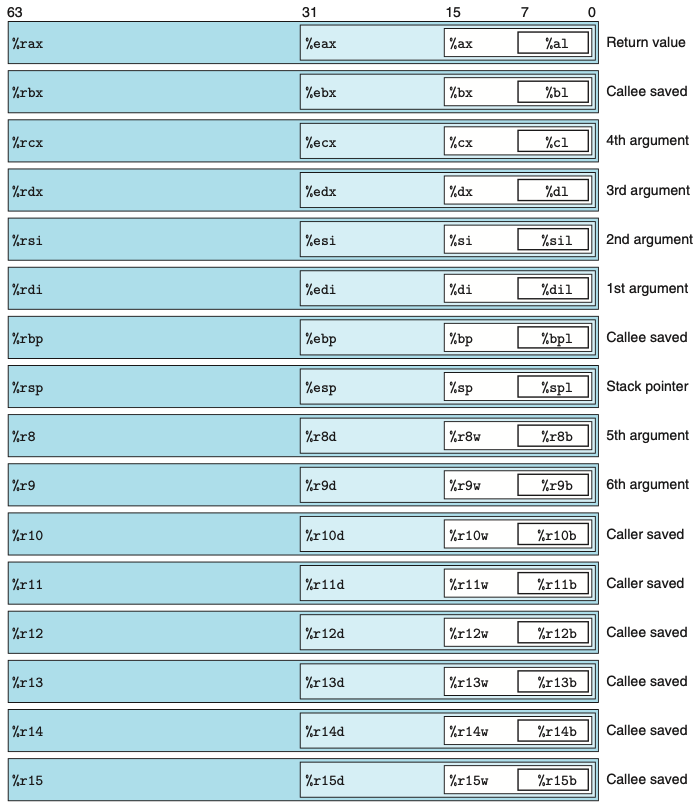
x86-64 的 CPU 包含 16 个储存 64 位通用寄存器,其中%rax 到 %rsp 比较常用,而 %r8 到 %r15 是从 32 位转了 64 位新加的。为了兼容 32 位(%eax 到 %esp)和 16 位(%ax 到 %sp)机保持兼容,对应低位表示。如:32 位只能访问低 4 位字节。
%rax一般用作累加器(Accumulator)%rbx一般用作基址寄存器( Base )%rxc一般用来计数( Count )%rdx一般用来存放数据( Data )%rsi一般用作源变址( Source Index )%rdi一般用作目标变址( DestinatinIndex )%rbp一般用作基址指针( Base Pointer )%rsp一般用作堆栈指针( Stack Pointer )
除此之外还有:
%rip是指令指针,也称为 PC- CF、ZF、SF 和 OF 条件码
下面我们通过 movq 这个指令来了解操作数的三种基本类型:立即数(Imm)、寄存器值(Reg)和内存值(Mem)。
| Source | Dest | movq Src, Dest | C Analog |
|---|---|---|---|
| Imm | Reg | movq $0x4, %rax |
temp = 0x4 |
| Imm | Mem | movq $-147, (%rax) |
*p = -147 |
| Reg | Reg | movq %rax, %rdx |
temp2 = temp1 |
| Reg | Mem | movq %rax, (%rdx) |
*p = temp |
| Mem | Reg | movq (%rax), %rdx |
temp = *p |
注意:是没有 movq Mem, Mem 的,不能用一条指令完成内存中的数据交换。
下面看看几种寻址的方式:
| 表示 | 计算方式 |
|---|---|
(R) |
Mem[Reg[R]] |
D(R) |
Mem[Reg[R] + D] |
D(Rb, Ri, S) |
Mem[Reg[Rb]+S*Reg[Ri]+D] |
其中:
D- 常数偏移量Rb- 基寄存器Ri- 索引寄存器,不能是 %rspS- 系数
我们通过具体的例子来巩固一下,这里假设 %rdx 中的存着 0xf000,%rcx 中存着 0x0100,那么
0x8(%rdx)=0xf000+0x8=0xf008(%rdx, %rcx)=0xf000+0x100=0xf100(%rdx, %rcx, 4)=0xf000+4*0x100=0xf4000x80(, %rdx, 2)=2*0xf000+0x80=0x1e080
操作指令
加载有效指令 leaq Src, Dst(load effective address),其中 Src 是地址的表达式,然后把计算的值存入 Dst 指定的寄存器。指的是从内存读取数据到寄存器中,但实际上没有引用内存。类似于 C 语言的 Dst = &Src。
我们通过一个例子来看:
long m12(long x) { |
对应的汇编:
leaq (%rdi, %rdi, 2), %rax # t <- x+x*2 |
直接对 %rdi 计算,然后赋值给 %rax
两个操作数指令:
addq Src, Dest->Dest = Dest + Srcsubq Src, Dest->Dest = Dest - Srcimulq Src, Dest->Dest = Dest * Srcsalq Src, Dest->Dest = Dest << Srcsarq Src, Dest->Dest = Dest >> Src(算术)shrq Src, Dest->Dest = Dest >> Src(逻辑)xorq Src, Dest->Dest = Dest ^ Srcandq Src, Dest->Dest = Dest & Srcorq Src, Dest->Dest = Dest | Src
一个操作数指令:
incq Dest->Dest = Dest + 1decq Dest->Dest = Dest - 1negq Dest->Dest = -Destnotq Dest->Dest = ~Dest
控制
到目前为止,我们只考虑了顺序执行,还有一些比如:条件语句、循环和分支语句,是根据测试结果来决定执行顺序。
条件码
我们用一个加法运算来说明,t = a + b ,对应的汇编为 addq Src, Dst 具体判断如下:
| 条件码 | 含义 | 判断 | 说明 |
|---|---|---|---|
| CF | 进位标志(Carry Flag) | (unsigned) t < (unsigned) a |
无符号溢出 |
| ZF | 零标志(Zero Flag) | t == 0 |
零 |
| SF | 符号标志(Sign Flag) | t < 0 |
负数 |
| OF | 溢出标志(Overflow Flag) | (a > 0 && b > 0 && t < 0) || (a < 0 && b < 0 && t > 0) |
有符号溢出 |
访问条件码
条件码通过一定的组合可以得到一些判断条件:
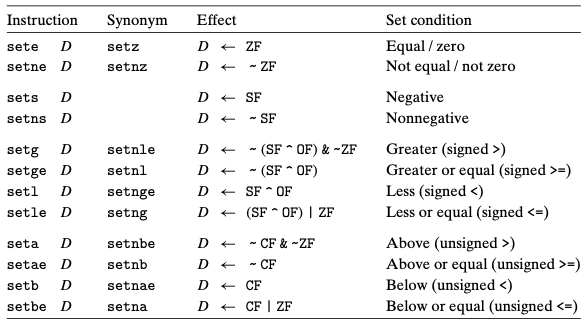
通过一个例子来看:
int gt(long x, long y) { |
对应汇编代码,%rdi 存储 x,%rsi 储存 y,%rax 表示返回值
comq %rsi, %rdi # 比较 x 和 y |
跳转指令
正常情况下指令是一条一条顺序执行,跳转指令(jump)会使程序切换到一个全新的位置。
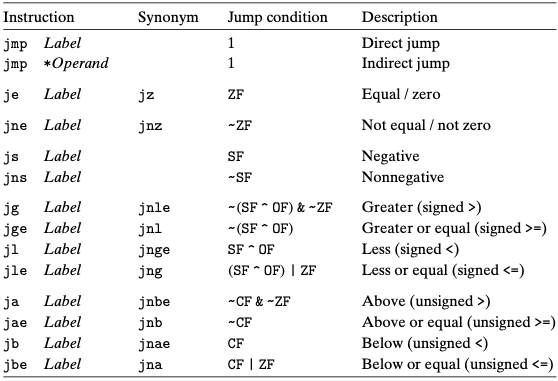
通过一个例子来看:
long absdiff(long x, long y) { |
没有优化,对应汇编代码,%rdi 存储 x,%rsi 储存 y,%rax 表示返回值
absdiff: |
我们知道 CPU 比较喜欢顺序工作,执行一系列操作会有缓存,所以效率比较高,如果遇到分支,会打破这种顺序工作,带来很大的性能影响。因此人们通常使用分支预测来解决,如果只是对这种简单的分支可以直接把两种结果直接算出来。简化为我们熟知的二元运算 test ? then_expr : else_expr 。
优化后,对应的汇编代码
absdiff: |
需要注意的是,有些场景不适合:
- 如果两个分支比较大的计算量
- 如果两个计算会相互影响
循环
看看 do-while 语句
long pcount_do(unsigned long x) |
和对应的汇编
movl $0, %eax # result = 0 |
过程调用
过程调用是一个是软件中一个很重要的抽象,提供了一种封装代码方式,在不同编程语言中有不同的形式,如:函数(function)、方法(method)、子例程(subroutine)和处理函数(handler)等。但这些都必须满足如下:
- 传递控制:包括如何开始执行过程代码,以及如何返回到开始的地方
- 传递数据:包括过程需要的参数以及过程的返回值
- 内存管理:如何在过程执行的时候分配内存,以及在返回之后释放内存
栈结构
当 x86-64 过程调用中所需要的存储空间超过了寄存器能够存放的大小时,就会在栈上分配空间,这个空间叫作栈帧(stack fram)。栈可以用来传递参数、存储返回信息、保存寄存器和局部变量等。
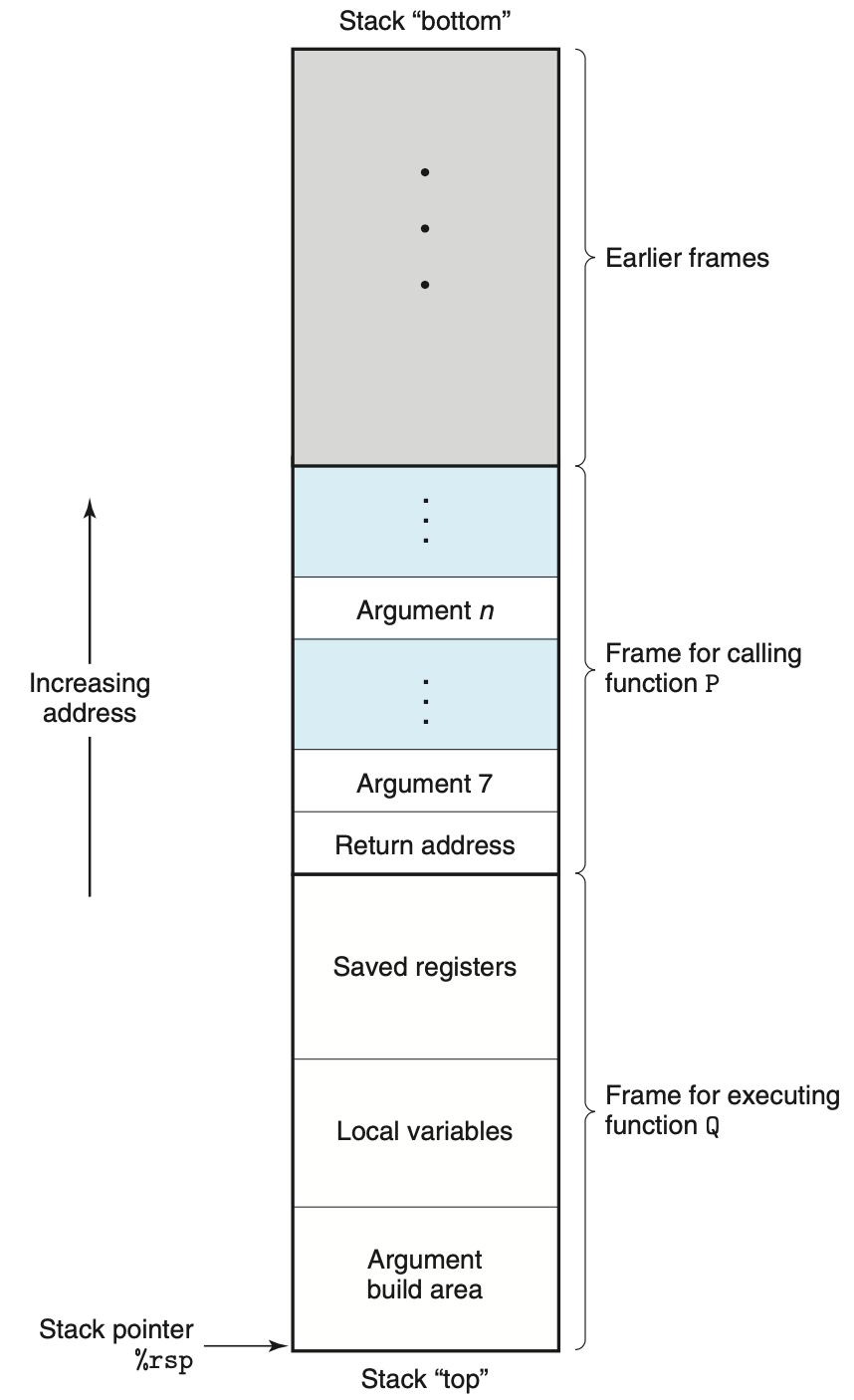
重要指令:
call Lable过程调用,直接调用- push 返回地址到栈中
- 跳到 label
ret从过程调用中返回- pop 地址从栈中
- 跳到对应地址
接下来我看一个过程调用的例子:
void multstore (long x, long, y, long *dest) { |
对应的汇编
0000000000400540 <multstore>: |
- 在 ret 之前会释放栈,比如前面通过
subq $32,%rsp分配了空间,后面就会通过addq $32, %rsp释放 - 如果参数超过了 6 个,寄存器放不下就会放到栈帧中
总结
本文简单介绍 x86-64 汇编相关内容,主要介绍了一下汇编中的常用指令和使用,除了一些逆向工程师和一些底层专业人员需要比较深入了解汇编,大多数开发,并不需要写汇编语言,但是希望自己能够阅读和理解一些简单汇编代码,主要为了 Boom Lab 做准备。
参考
- 深入理解计算机系统
- 机器指令和程序优化

