
Netty 源码分析(五)
版本 4.1.15
Netty is an asynchronous event-driven network application framework for rapid development of maintainable high performance protocol servers & clients.
ReferenceCounted
io.netty.util.ReferenceCounted
引用计数文档
public interface ReferenceCounted
A reference-counted object that requires explicit deallocation.
When a new ReferenceCounted is instantiated, it starts with the reference count of 1. retain() increases the reference count, and release() decreases the reference count. If the reference count is decreased to 0, the object will be deallocated explicitly, and accessing the deallocated object will usually result in an access violation.
If an object that implements ReferenceCounted is a container of other objects that implement ReferenceCounted, the contained objects will also be released via release() when the container’s reference count becomes 0.
我们看看其中的方法
public interface ReferenceCounted { |
AbstractReferenceCountedByteBuf
io.netty.buffer.AbstractReferenceCountedByteBuf
我们先来看两个比较重要的方法,retain() 和 release() 方法
retain()
io.netty.buffer.AbstractReferenceCountedByteBuf#retain()
retain() 方法可以使引用计数加一
|
java.util.concurrent.atomic.AtomicIntegerFieldUpdater
public abstract class AtomicIntegerFieldUpdater
extends Object
A reflection-based utility that enables atomic updates to designated volatile int fields of designated classes. This class is designed for use in atomic data structures in which several fields of the same node are independently subject to atomic updates.
Note that the guarantees of the compareAndSet method in this class are weaker than in other atomic classes. Because this class cannot ensure that all uses of the field are appropriate for purposes of atomic access, it can guarantee atomicity only with respect to other invocations of compareAndSet and set on the same updater.
AtomicIntegerFieldUpdater要点的总结:
- 更新器必须是int类型的变量,不能是其他包装类型
- 更新器的更新必须是volatile类型的变量,确保线程之间的共享变量时的立即可见性
- 变量不能是static的,必须是实例变量,因为Unsafe.objectFieldOffset() 方法不支持静态变量(CAS操作本质是通过对象实例的偏移来直接进行赋值)
- 更新器只能修改它可见范围内的变量,因为更新器是通过反射来得到这个变量,如果变量不可见就会报错
如果更新的变量时包装类型,那么可以使用AtomicReferenceFieldUpdater来进行更新
java.util.concurrent.atomic.AtomicIntegerFieldUpdater#compareAndSet
public abstract boolean compareAndSet(T obj,
int expect,
int update)
Atomically sets the field of the given object managed by this updater to the given updated value if the current value == the expected value. This method is guaranteed to be atomic with respect to other calls to compareAndSet and set, but not necessarily with respect to other changes in the field.
Parameters:
obj - An object whose field to conditionally set
expect - the expected value
update - the new value
一个不安全的更新
/** |
使用AtomicIntegerFieldUpdater
/** |
大概有以下两种字段适合用Atomic*FieldUpdater:
大多数用到这个字段的代码是在读取字段的值, 但仍然有通过CAS更新字段值的需求. 这个时候用AtomicInteger的话每个直接读取这个字段的地方都要多一次.get()调用, 用volatile又满足不了需求, 所以就用到了AtomicIntegerFieldUpdater
这个字段所属的类会被创建大量的实例对象, 如果用AtomicInteger, 每个实例里面都要创建AtomicInteger对象, 从而多出内存消耗. 比如一个链表类的Node, 用AtomicReference保存next显然是不合适的.
原文:https://blog.csdn.net/u012415542/article/details/80646605
private static final AtomicIntegerFieldUpdater<AbstractReferenceCountedByteBuf> refCntUpdater = |
Reference counted objects
引用计数文档:Reference counted objects
Netty 处理器
重要概念
- Netty 的处理器可以分为两类:入站处理器和出站处理器
- 入站处理器的顶层是 ChannelnboundHandler,出站处理器的顶层是 ChannelOutboundHandler
- 数据处理时常用的各种解码器本质上都是处理器
- 编解码器:无论我们向网络中写入的数据是什么类型,数据在网络中传递时,其都是以字节流的形式呈现,将数据有原本的字节流的操作成为编码(encode),将数据有字节转化为它原本的格式或是其它的操作成为解码(decode),编码统一称为(codec)
- 编码:本质上是一种出站处理器,因此,编码一定是一种 ChannelOutboundHandler
- 解码:本质上是一种入站处理器,因此,解码一定是一种 ChannelInboundHandler
- 在 Netty 中,编码器通常以 xxxEncoder命名;解码器通常以xxxDecoder命名
编写一个Long类型的解码器
编写一个解码器在客服端与服务端传输一个 Long 型的数据,Netty 为我们提供了 ByteToMessageDecoder
io.netty.handler.codec.ByteToMessageDecoder
io.netty.handler.codec
public abstract class ByteToMessageDecoder
extends ChannelInboundHandlerAdapter
ChannelInboundHandlerAdapter which decodes bytes in a stream-like fashion from one ByteBuf to an other Message type. For example here is an implementation which reads all readable bytes from the input ByteBuf and create a new ByteBuf.
public class SquareDecoder extends ByteToMessageDecoder {
@Override
public void decode(ChannelHandlerContext ctx, ByteBuf in, ListFrame detection
Generally frame detection should be handled earlier in the pipeline by adding a DelimiterBasedFrameDecoder, FixedLengthFrameDecoder, LengthFieldBasedFrameDecoder, or LineBasedFrameDecoder.
If a custom frame decoder is required, then one needs to be careful when implementing one with ByteToMessageDecoder. Ensure there are enough bytes in the buffer for a complete frame by checking ByteBuf.readableBytes(). If there are not enough bytes for a complete frame, return without modifying the reader index to allow more bytes to arrive.
To check for complete frames without modifying the reader index, use methods like ByteBuf.getInt(int). One MUST use the reader index when using methods like ByteBuf.getInt(int). For example calling in.getInt(0) is assuming the frame starts at the beginning of the buffer, which is not always the case. Use in.getInt(in.readerIndex()) instead.
Pitfalls
Be aware that sub-classes of ByteToMessageDecoder MUST NOT annotated with @Sharable.
Some methods such as ByteBuf.readBytes(int) will cause a memory leak if the returned buffer is not released or added to the out List. Use derived buffers like ByteBuf.readSlice(int) to avoid leaking memory.
MyByteToLongDecoder
/** |
MyLongToByteEncoder
/** |
重要结论:
- 无论是编码器还是解码器,其所接收的消息类型必须要与待处理的参数保持一致,否则该编码器或则解码器不会被执行
- 在解码器进行数据解码时,一定要记得判断缓冲(ByteBuf)中的数据是否足够,否则将会产生一些问题
ReplayingDecoder
文档:https://netty.io/4.1/api/io/netty/handler/codec/ReplayingDecoder.html
如果我们使用这个继承这个编码器,他会自动帮我判断是否可读,代码也简单,简化了我们的判断
public class MyByteToLongDecoder2 extends ReplayingDecoder<Void> { |
LengthFieldBasedFrameDecoder
io.netty.handler.codec.LengthFieldBasedFrameDecoder
文档:https://netty.io/4.1/api/io/netty/handler/codec/LengthFieldBasedFrameDecoder.html
这是一个常用语自定义协议的解码器
TCP 粘包拆包
如果我写的自定义协议没有对粘包和拆包做特殊处理的话就会产生粘包和拆包现象
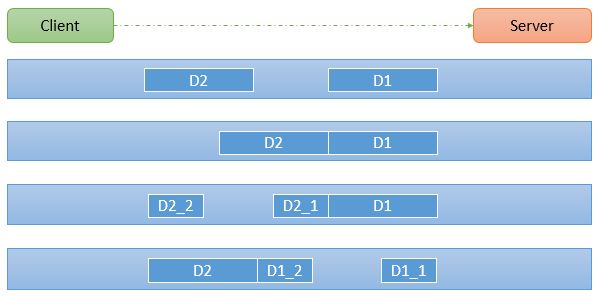
粘包、拆包发生原因
发生TCP粘包或拆包有很多原因,现列出常见的几点,可能不全面,欢迎补充,
1、要发送的数据大于TCP发送缓冲区剩余空间大小,将会发生拆包。
2、待发送数据大于MSS(最大报文长度),TCP在传输前将进行拆包。
3、要发送的数据小于TCP发送缓冲区的大小,TCP将多次写入缓冲区的数据一次发送出去,将会发生粘包。
4、接收数据端的应用层没有及时读取接收缓冲区中的数据,将发生粘包。
粘包、拆包解决办法
通过以上分析,我们清楚了粘包或拆包发生的原因,那么如何解决这个问题呢?解决问题的关键在于如何给每个数据包添加边界信息,常用的方法有如下几个:
1、发送端给每个数据包添加包首部,首部中应该至少包含数据包的长度,这样接收端在接收到数据后,通过读取包首部的长度字段,便知道每一个数据包的实际长度了。
2、发送端将每个数据包封装为固定长度(不够的可以通过补0填充),这样接收端每次从接收缓冲区中读取固定长度的数据就自然而然的把每个数据包拆分开来。
3、可以在数据包之间设置边界,如添加特殊符号,这样,接收端通过这个边界就可以将不同的数据包拆分开。作者:wxy941011
来源:CSDN
原文:https://blog.csdn.net/wxy941011/article/details/80428470
版权声明:本文为博主原创文章,转载请附上博文链接!
自定义协议解决粘包和拆包
一个 Person 协议类
/** |
解码处理器
/** |
编码处理器
/** |
服务端
/** |
客服端
public class MyClient { |
总结
这里关于 Netty 的这五篇分析都是看的圣思园张龙老师的课程自己所写下的笔记,自己对 Netty 有了简单的认识,也对 NIO 有了更深的了解,最主要的学会看英文文档,看官方文档很重要,不要惧怕,慢慢的就感觉还是文档写的最清楚,最有价值。老师还提到需要多记录,因此我也把一些重要的知识点记录下来,方便以后查找。当然以后还要加强学习,多看看 Netty 官方文档和例子,加强练习。

