
Netty 源码分析(四)
版本 4.1.15
Netty is an asynchronous event-driven network application framework for rapid development of maintainable high performance protocol servers & clients.
ChannelPromise
io.netty.channel.ChannelPromise
前面我们分析了 ChannelFuture ,看看ChannelPromise 的作用
/** |
这是一个可以写入的 ChannelFuture ,我先看看 Promise 这个类
Promise
io.netty.util.concurrent.Promise
public interface Promise<V> extends Future<V> { |
JDK 所提供的的 Future 只能通过手工的方式检查执行结果,而这个操作是会阻塞的;Netty 则对 ChannelFutre 进行了增强,通过 ChannelFutureListener 以回调的方式来获取执行结果,去除了手工检查阻塞的操作,值得注意的是,ChannelFutrureListener 的 operationComplete 方法是由I/O线程执行的,因此要注意的是不要在这里执行耗时操作,否则需要通过另外的线程或线程池来执行
ChannelInboundHandlerAdapter
io.netty.channel.ChannelInboundHandlerAdapter
io.netty.channel
public class ChannelInboundHandlerAdapter
extends ChannelHandlerAdapterimplements ChannelInboundHandlerAbstract base class for ChannelInboundHandler implementations which provide implementations of all of their methods.
This implementation just forward the operation to the next ChannelHandler in the ChannelPipeline. Sub-classes may override a method implementation to change this.
Be aware that messages are not released after the channelRead(ChannelHandlerContext, Object) method returns automatically. If you are looking for a ChannelInboundHandler implementation that releases the received messages automatically, please see SimpleChannelInboundHandler.
这里使用了适配器模式
ChannelInboundHandler
io.netty.channel.ChannelInboundHandler
/** |
SimpleChannelInboundHandler
io.netty.channel.SimpleChannelInboundHandler
我们在写自己的 Handler 的时候长会继承这个 SimpleChannelInboundHandler
public class MyServerHandler extends SimpleChannelInboundHandler<String>{ |
我们看看这个文档
io.netty.channel
public abstract class SimpleChannelInboundHandler
extends ChannelInboundHandlerAdapter
ChannelInboundHandlerAdapter which allows to explicit only handle a specific type of messages. For example here is an implementation which only handle String messages.
SimpleChannelInboundHandler<String> {
protected void channelRead0(ChannelHandlerContext ctx, String message)
throws Exception {
System.out.println(message);
}
}Be aware that depending of the constructor parameters it will release all handled messages by passing them to ReferenceCountUtil.release(Object). In this case you may need to use ReferenceCountUtil.retain(Object) if you pass the object to the next handler in the ChannelPipeline.
Forward compatibility notice
我们可以通过泛型指定消息类型
|
给我们强制转换为特定的类型,再调用 channelRead0 方法,这是一个抽象方法,需要我们自己去实现
ReferenceCounted
io.netty.util.ReferenceCounted
io.netty.util
public interface ReferenceCounted
A reference-counted object that requires explicit deallocation.
When a new ReferenceCounted is instantiated, it starts with the reference count of 1. retain() increases the reference count, and release() decreases the reference count. If the reference count is decreased to 0, the object will be deallocated explicitly, and accessing the deallocated object will usually result in an access violation.
If an object that implements ReferenceCounted is a container of other objects that implement ReferenceCounted, the contained objects will also be released via release() when the container’s reference count becomes 0.
ctx.channel().write()和ctx.write()的区别
在 Netty 中有两种发消息的方式,可以直接写到 Channel 中,也可以写到与 ChannelHandler 所关联的那个 ChannelHandlerContext 中,对于 ctx.channel().write() 方式来说,消息会从 ChannelPipeline 的末尾开始流动,对于 ctx.write() 来说,消息将从 ChannelPipeline 中的下一个 ChannelHandler 开始流动
这篇博客个解释了
https://blog.csdn.net/FishSeeker/article/details/78447684
结论:
- ChannelHandlerContext 与 ChannelHandler 之间的关联绑定关系是永远不会发生改变的,因此对其进行缓存时没有任何问题的
- 对于与 Channel 的同名方法来说, ChannelHandlerContext 的方法将会产生更短的事件流,所以我们因该在可能的情况下利用这个特性来提升性能
Java NIO
NIO 总结
使用 NIO 进行文件读取所涉及的步骤:
- 从 FileInputStream 对象获取到 Channel 对象
- 创建 Buffer
- 将数据从 Channel 中读取到Buffer中
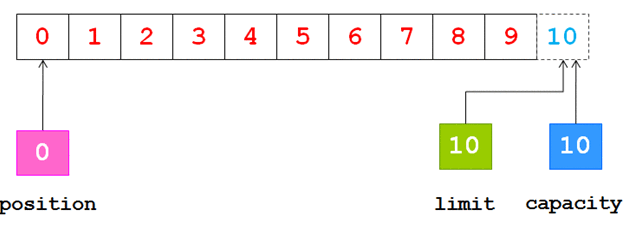
0 <= mark <= position <= limit <= capacity
flip() 方法:
- 将 limit 值设置为当前的 position
- 将 position 设置 0
clear() 方法:
- 将 limit 设置为capacity
- 将 position 设置为0
compact() 方法:
- 将所有未读的数据复制到 buffer 起始的位置处
- 将 position 设置为最后一个未读元素的后面
- 将 limit 设置为 capacity
- 现在buffer 就准备好了,但是不会覆盖未读的数据
Java NIO中,关于DirectBuffer,HeapBuffer的疑问?
DirectBuffer 属于堆外存,那应该还是属于用户内存,而不是内核内存?
FileChannel 的read(ByteBuffer dst)函数,write(ByteBuffer src)函数中,如果传入的参数是HeapBuffer类型,则会临时申请一块DirectBuffer,进行数据拷贝,而不是直接进行数据传输,这是出于什么原因?
答案: https://www.zhihu.com/question/57374068/answer/152691891
Java NIO中的direct buffer(主要是DirectByteBuffer)其实是分两部分的:
Java | native |
其中 DirectByteBuffer 自身是一个Java对象,在Java堆中;而这个对象中有个long类型字段address,记录着一块调用 malloc() 申请到的native memory。
所以回到题主的问题:
\1. DirectBuffer 属于堆外存,那应该还是属于用户内存,而不是内核内存?
DirectByteBuffer 自身是(Java)堆内的,它背后真正承载数据的buffer是在(Java)堆外——native memory中的。这是 malloc() 分配出来的内存,是用户态的。
\2. FileChannel 的read(ByteBuffer dst)函数,write(ByteBuffer src)函数中,如果传入的参数是HeapBuffer类型,则会临时申请一块DirectBuffer,进行数据拷贝,而不是直接进行数据传输,这是出于什么原因?
题主看的是OpenJDK的 sun.nio.ch.IOUtil.write(FileDescriptor fd, ByteBuffer src, long position, NativeDispatcher nd) 的实现对不对:
static int write(FileDescriptor fd, ByteBuffer src, long position, |
这里其实是在迁就OpenJDK里的HotSpot VM的一点实现细节。
HotSpot VM里的GC除了CMS之外都是要移动对象的,是所谓“compacting GC”。
如果要把一个Java里的 byte[] 对象的引用传给native代码,让native代码直接访问数组的内容的话,就必须要保证native代码在访问的时候这个 byte[] 对象不能被移动,也就是要被“pin”(钉)住。
可惜HotSpot VM出于一些取舍而决定不实现单个对象层面的object pinning,要pin的话就得暂时禁用GC——也就等于把整个Java堆都给pin住。HotSpot VM对JNI的Critical系API就是这样实现的。这用起来就不那么顺手。
所以 Oracle/Sun JDK / OpenJDK 的这个地方就用了点绕弯的做法。它假设把 HeapByteBuffer 背后的 byte[] 里的内容拷贝一次是一个时间开销可以接受的操作,同时假设真正的I/O可能是一个很慢的操作。
于是它就先把 HeapByteBuffer 背后的 byte[] 的内容拷贝到一个 DirectByteBuffer 背后的native memory去,这个拷贝会涉及 sun.misc.Unsafe.copyMemory() 的调用,背后是类似 memcpy() 的实现。这个操作本质上是会在整个拷贝过程中暂时不允许发生GC的,虽然实现方式跟JNI的Critical系API不太一样。(具体来说是 Unsafe.copyMemory() 是HotSpot VM的一个intrinsic方法,中间没有safepoint所以GC无法发生)。
然后数据被拷贝到native memory之后就好办了,就去做真正的I/O,把 DirectByteBuffer 背后的native memory地址传给真正做I/O的函数。这边就不需要再去访问Java对象去读写要做I/O的数据了。
ByteBuf
文档:https://netty.io/4.1/api/index.html
我们看第一个例子
public class ByteBufTest01 { |
输出:
120 |
我们来看看这个方法的文档
/** |
虽然传入的一个 int 值,可是它会丢弃高位的 24 bit,我们知道 int 是 4 字节(32 bit),丢弃 3 字节 (24 bit),就保留到 1 字节(8 bit)
我们要看下一个例子
public class ByteBufTest02 { |
输出:
hello world |
ridx 表示读的 index,widx 表示写的 index
我们来看看复合 Buffer
public class ByteBufTest03 { |
Netty 提供的 3 种缓冲区
heap buffer(堆缓冲区):
这是最常见的类型,ByteBuf 将数据存储到 JVM 的堆空间中,并且将实际的数据放到 byte 数组中来实现的
优点:由于数据是存储在 JVM 的堆中,因此可以快速的创建和快速的释放,并且它提供了 直接访问内部字节数组的方法
缺点:每次读写数据时,都需要先将数据复制到直接缓冲中再进行网络传输
direct buffer(直接缓冲区):
在堆之外直接分配内存空间,直接缓冲区并不会占用堆的容量空间,因为他是有操作系统在本地内存进行的数据分配
优点:在使用 Socket 进行数据传输时,性能非常好,因为数据直接位于操作系统的本地内存中,所以不需要从 JVM 将数据复制到直接缓冲区
缺点:因为 Direct Buffer 是直接在操作系统内存中的,所以内存空间分配与释放要比堆空间更加复杂,而且速度要慢一些
Netty 通过提供内存池来解决这个问题,直接缓冲区并不支持通过字节数组的方式来访问数据
重点:对于后端的业务消息的编解码来说,推荐使用 HeapByteBuf;对于 I/O 通信的读写缓冲区,我们推荐使用 DirectBytebuf
composite buffer(符合缓冲区):
复合缓冲区实际上是将多个缓冲区实例组合起来,并向外提供一个统一视图。像是一个缓冲区的 List
JDK 的 ByteBuffer 与 Netty 的 ByteBuf 之间的差异比对
- Netty 的 ByteBuf 采用了读写分离的策略(readerIndex 和 writeerIndex),一个初始化(里面尚未有任何数据)的 ByteBuf 的 readerIndex 与 writerIndex 的值都为0
- 当数索引与写索引处于同一个位置时,如果我们继续读取,那么就会抛出 IndexOutOfBoundsException
- 对于ByteBuf 的任何读写操作都会分别单独维护读索引和写索引,MaxCapacity 最大的容量默认为Integer.MAX_VALUE

JDK 的 ByteBuffer的缺点:
- final byte[] hb; 这是JDK的ByteBuffer对象中用于储存的对象声明,可以看到,其字节数组布尔声明为final的,也就是长度是固定不变的,一旦分配好后就不能动态扩容与收缩,而且当储存的数据字节很大时就很有可能出现IndexOutOfBoundsException,如果要预防着个异常,那就需要再储存之前完全确定好待储存的字节的大小,如果ByteBuffer的空间不足,我们只有一种解决方案,那就是创建新的ByteBuffer对象,然后再将之前的ByteBuffer中的数据复制过去,这一切操作都需要由开发者自己来手动完成的
- ByteBuffer 只使用一个position 指针来标识位置信息,在进行读写切换时就需要调用flip方法或则是rewind 方法,使用很不方便
Netty 的 ByteBuf 的优点:
- 储存字节的数组是动态的,其最大值默认是Integer.MAX_VALUE,这里的动态性是体现在write方法中的,write方法执行会判断buffer容量,如果不足则会自动扩容
- ByteBuf的读写索引是完成分开的,使用起来很方便
// io.netty.buffer.AbstractByteBuf#writeByte |

